SeqTrans: Automatic Vulnerability Fix via Sequence to Sequence Learning¶
Link: https://arxiv.org/pdf/2010.10805
Problem to Solve¶
Software vulnerability can be viewed as a specific category of bugs that are still mainly solved by programmers’ manual efforts. An automated method based on Neural Machine Translation (NMT), which is previously used for bugs repairs, can also be transfered to target on the vulnerability fixes after fine-tuning.
Methodology¶
Overview¶
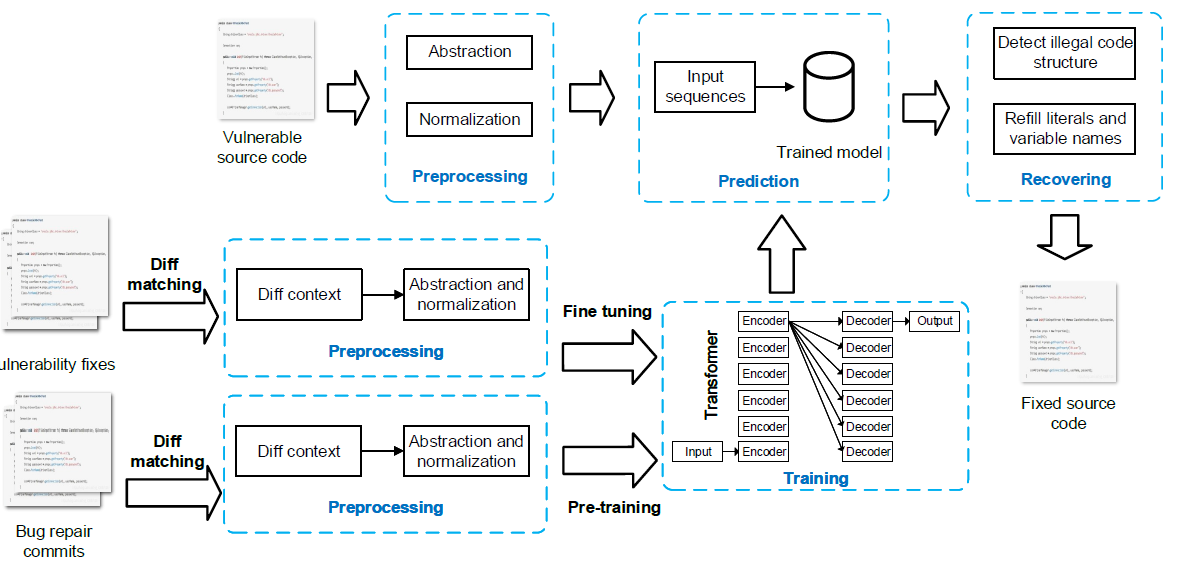
Preprocessing:
extract diff contexts from two datasets: bug repair (large) and vulnerability fixing (small)
abstraction + normalization on data-flow denpendencies -> def-use chains
Pre-training and fine-tuning:
train a model on bug repair dataset (large)
fine tune on vulnerability fixing dataset (small)
Prediction and patching
input: one vulnerable file
oversimplied assumption: no consider how to locate the vulnerability (location tools + human security specialist)
model provides multiple candidates for users to select the most suitable prediction.
syntax checker Findbugs checks the error and filter the predictions containing sytanx error
refill abstraction and generate patches
Preprocessing¶
Crawl git difffiles, search for code diff on ASTs:
GumTree (find out diff mappings:)
Greedy top-down: find isomorphic sub-trees of decreasing height
bottom up: if two nodes’ descendants include a large number of common anchors
Then it extract data flow dependencies around code diffs to construct our def-use chains.
All global variables will be preserved.
All statements that have data dependencies on the vulnerable statement will be retained
Test.java: source
class Foo {
int i;
int k;
String test;
public void clear(String test){
test = "";
}
private String foo(int i, int k) {
if(i == k) return i-k;
}
}
Test.java: buggy body
int i;
int k;
String test;
private String foo(int i, int k) {
if(i == k) return i-k;
}
Normalization & Tokenization¶
To reduce the vocabulary size:
Normalization: replace value by tokens
Tokenization: Byte Pair Encoding to replace several tokens into one
Test.java: source
private String foo(int i, int k) {
if(i == 0) return "Foo!";
if(k == 1) return 0;}
Test.java: normalized source
private String foo(int var1, int var2) {
if(var1 == num1) return "str";
if(var2 == num2) return num1;}
Pre-train and tune¶
The transformer model comes from an open-source neural machine translation framework Open-NMT: more parallel and achieves better translation results. There are very few such pretrained models in the Programming language (PL) field.
Choose the best-perfom model trained on generic dataset (bug repair) and then fine-tune on specific dataset (vulnerability fixing).
Prediction and Patch Generation¶
Feed the model with the structure extract from vulnerability location and get an output as several candidates, choose the most situable one:
Beam Search: when the certain domain-specific knowledge is given, expands all possible next steps and keeps the \(k\) most likely, where \(k\) is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Abstraction Refill: “reversed” normalization and tokenization
Syntax Check: Filter out those with syntax errors